
Künstliche Intelligenz
KI in der Arbeitswelt – der Einsatz Künstlicher Intelligenz braucht viel menschliche Kompetenz
Veröffentlicht am 09. Jul 2020
Die Informatikprofessorin und KI-Expertin Dr. Katharina Zweig spricht im Interview über den Einsatz von KI im Bereich Arbeit und Soziales, den nötigen Aufbau von Kompetenzen zu KI und darüber welche KI-Systeme wie reguliert werden sollten.
Frau Zweig, sind sich die politischen Entscheidungsträger in Deutschland und Europa darüber im Klaren, welche Veränderungen Künstliche Intelligenz (KI) mit sich bringen wird?
ZWEIG: Ich glaube, dass das sehr heterogen ist. In der Enquete-Kommission Küstliche Intelligenz im Bundestag sitzen natürlich genau die Abgeordneten, die sich schon mit diesen Themen auseinandergesetzt haben. Ansonsten sehe ich die volle Bandbreite: Eine Bezirksregierung, die sich für solche Fragen interessiert, auch manche Landesregierungen, merken auf. Und wir haben gerade mit Gerald Swarat vom Fraunhofer eine Initiative für KI in Kommunen aufgesetzt, wo es im Wesentlichen darum geht, erst einmal aufzuklären – wir haben nämlich die Sorge, dass sonst KI-Systeme zu schnell und ohne Kenntnis, wie die Technologie funktioniert, gekauft werden.
Gibt es typische Fehlannahmen zu KI, denen Sie immer wieder begegnen?
ZWEIG: Es gibt diese diffuse Idee, dass eine KI klug sei. Sehr oft wird dabei der Grundmechanismus nicht verstanden – nämlich, dass die Methoden, die heute so viel diskutiert sind, einfach statistische Verfahren sind, die nach Mustern in Daten suchen. Und es ist vielen Menschen nicht bewusst, wie viele Steuerungsmöglichkeiten es dabei gibt. Sie haben das Gefühl, dass die Maschine eine optimale und objektive Lösung errechnet. Aber dazu sind manche Fragestellungen immer noch zu komplex, insbesondere wenn es um Menschen geht.

Inwiefern?
ZWEIG: Bei komplexen Fragestellungen haben wir keine Algorithmen mehr, die tatsächlich ein Optimum finden könnten, sondern nur noch sogenannte Heuristiken. Diese Heuristiken versuchen in den Daten Muster zu finden, die möglichst aussagekräftig sind – sie können aber nicht garantieren, dass sie die besten Muster gefunden haben. Das heißt: Es kann je nach Datensatz und Fragestellung auch zu Fehlern kommen. Das ist den meisten nicht klar, und deswegen wird KI in manchen Bereichen zu viel zugetraut, während dieses Vertrauen in anderen Bereichen berechtigt ist.
Führt dieses übermäßige Zutrauen in KI dazu, dass Politik und Wirtschaft zu große Sorge hinsichtlich KI-Systemen haben – und zu stark regulieren wollen?
ZWEIG: Es gibt beides. Wenn man die Möglichkeiten von Künstlichen Intelligenzen stark überhöht, hat man auch das Gefühl, dass da Chancen für die Wirtschaft stecken, die man unbedingt freilassen muss. Und auf der anderen Seite gibt es den Wunsch nach starker Regulierung – und da müssen wir wirklich vorsichtig sein.
Warum?
ZWEIG: Es gibt eben nicht „die KI“. KI ist ein Methodenset, mit dem man versucht, aus Daten Muster zu extrahieren. Mein Forschungsgebiet betrifft diejenigen KI-Systeme, die mithilfe dieser gefundenen Muster dann Entscheidungen treffen. Und diese Entscheidungen sind so vielfältig wie die Entscheidungsträgerinnen und Entscheidungsträger, die sie ersetzen oder unterstützen sollen. Daher muss es bei der Regulierung einen Unterschied machen, ob mir jemand in einer öffentlichen Bibliothek ein Buch empfiehlt, ob mir ein*e Ärzt*in eine Diagnose stellt oder ob ein*e Richter*in entscheidet, wie lange ich ins Gefängnis muss. Und so ist es auch bei KI-Systemen.
Gibt es eine Faustregel, welche KI-Systeme wirklich reguliert werden sollten?
ZWEIG: Eigentlich nur diejenigen Systeme, deren Einsatz gesetzlich geregelte Bereiche betrifft. Ganz grob gesagt sind dies Systeme, die über Menschen urteilen, über das Hab und Gut von Menschen, oder KI-Systeme, die Zugang zu gesellschaftlichen oder natürlichen Ressourcen gewähren.
Welche Ressourcen konkret?
ZWEIG: Zugang zum Arbeitsmarkt, Zugang zum Wohnungsmarkt, Zugang zu Erdöl, Energie, Bildung – alles, was eine Ressource ist, die nicht in beliebiger Form zur Verfügung steht. Aber wenn es um die Frage geht: „Wie baue ich die beste Büroklammer?“ und man dann ein KI-System entwickelt, das diejenigen Büroklammern vom Band nimmt, die nicht ordentlich gefaltet sind – dann brauchen wir da sicherlich keine Regulierung.
Nach welchen Kriterien sollte bewertet werden, ob reguliert werden sollte und wie stark – oder nicht?
ZWEIG: Daran forschen wir gerade – einfache Regeln sind hier nicht leicht zu entwickeln, da es die oben schon erwähnte hohe Bandbreite an Anwendungskontexten gibt. Bei KI-Systemen, die Entscheidungen treffen oder unterstützen, kommt es aber im Wesentlichen darauf an, wie hoch das Schadenspotenzial eines KI-Systems in seiner Anwendung ist und wie stark jemand von dieser Entscheidung abhängig ist. Betrachten wir etwa ein Bewertungssystem für Bewerber*innen sowie Mitarbeiter*innen, dann macht es einen Unterschied, ob ich als Bewerber*in 200 Firmen anschreibe, die jeweils ein eigenes System haben – denn selbst wenn mich zehn Prozent dieser Systeme ablehnen, kann ich immer noch hoffen, dass die anderen 90 Prozent nach anderen Kriterien laufen. Oder ob dasselbe System interne Bewerber*innen beurteilt, denn dann ist der Grad der Abhängigkeit viel höher, weil ich ja nicht einfach die Firma wechseln kann, um mich anders bewerten zu lassen. Daran sieht man: Dasselbe System, in unterschiedliche soziale Prozesse integriert, bedarf unterschiedlich starker Kontrolle.
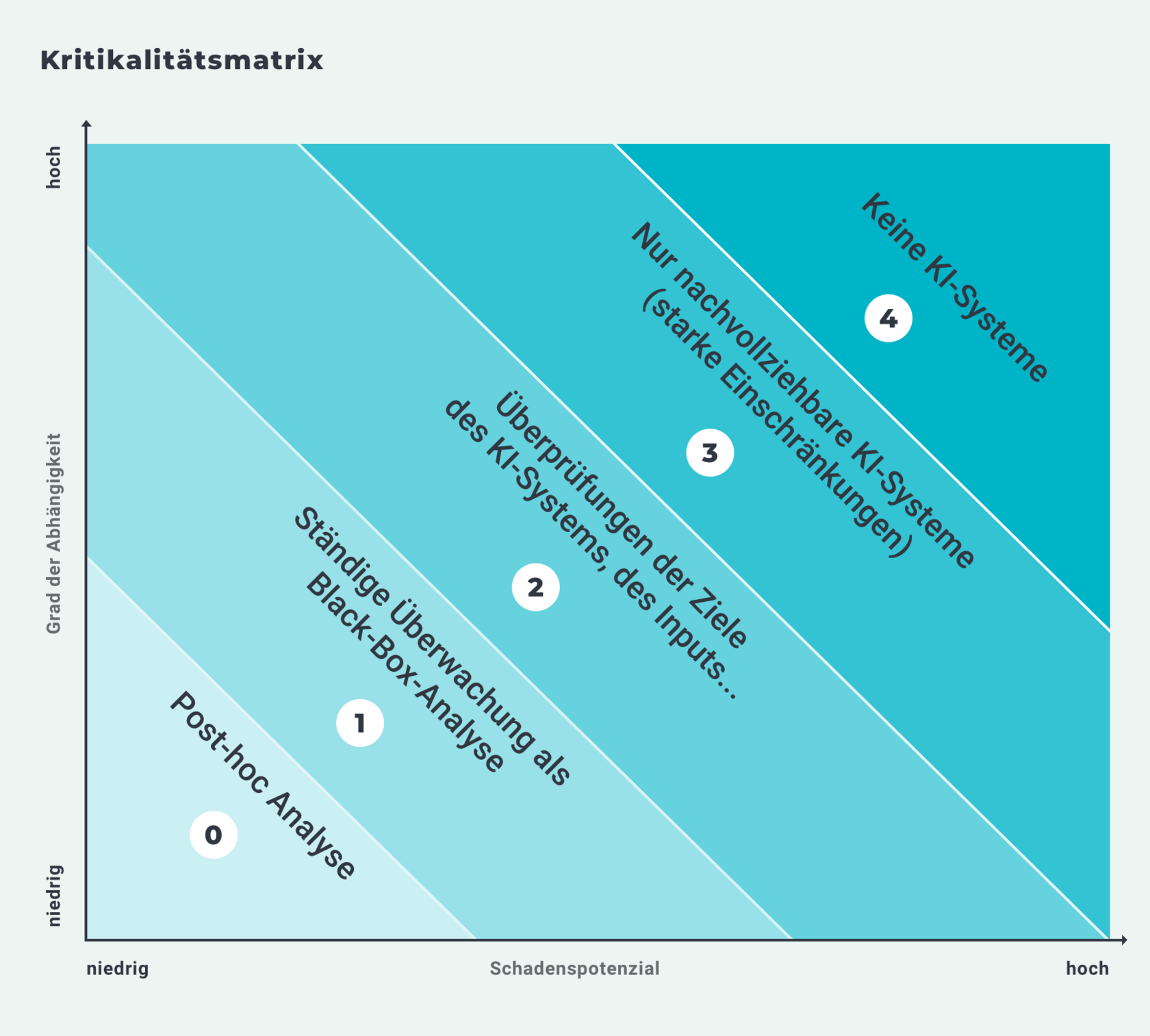
Übersicht
Die Abbildung 1 mit der Überschrift „Kritikalitätsmatrix“ enthält neben einem Achsendiagramm den folgenden beschreibenden Text: „Die Kritikalitätsmatrix von Tobias Krafft und Katharina Zweig unterscheidet fünf Kritikalitätsstufen der Anwendung von entscheidungsfällenden oder -unterstützenden KI-Systemen. Mit den aufeinander aufbauenden Klassen sind ansteigende Regulierungsanforderungen an die Transparenz und Nachvollziehbarkeit der Entscheidungslogik verknüpft“.
Datensatz
Auf der x-Achse des Achsendiagramms ist das Schadenspotenzial von entscheidungsfällenden oder -unterstützenden KI-Systemen von niedrig bis hoch abgetragen. Auf der y-Achse ist der Grad der Abhängigkeit dieser KI-Systeme von niedrig bis hoch abgetragen. Ausgehend vom Nullpunkt mit niedrigem Schadenspotenzial und niedrigem Grad der Abhängigkeit bis zum oberen rechten Ecke mit hohem Schadenspotenzial und hohem Grad der Abhängigkeit werden die fünf Kritikalitätsstufen mit gleichmäßigem Abstand dargestellt. Die erste Kritikalitätsstufe 0 trägt die Beschreibung „Post-hoc-Analyse“. Darauf folgen:
- Stufe 1 „Ständige Überwachung als Black-Box-Analyse“
- Stufe 2 „Überprüfungen der Ziele des KI-Systems, des Inputs, …“
- Stufe 3 „Nur nachvollziehbare KI-Systeme (starke Einschränkungen)“
- Stufe 4 „Keine KI-Systeme“.
Darstellung
Die Abbildung stellt mithilfe schräg angeordneter Balken von links unten nach rechts oben grafisch dar, wie die Regulierungsanforderungen an die Transparenz und Nachvollziehbarkeit der Entscheidungslogik von entscheidungsfällenden oder -unterstützenden KI-Systemen geknüpft sind. Die Grafik zeigt, dass die Regulierungsanforderungen mit dem Schadenspotenzial und dem Grad der Abhängigkeit ansteigen.
© Algorithm Accountability Lab [Prof. Dr. K. A. Zweig], http://aalab.cs.uni-kl.de/resources/.
Wie ist es konkret im Bereich Arbeit und Soziales? Gibt es da Interesse an den Veränderungen, die KI mit sich bringen wird?
ZWEIG: Betriebsräte sind schon sehr lange dabei, sich mit KI-Systemen zu befassen, sicherlich seit über fünf Jahren. Mit denen machen wir viel, und da sind wir jetzt kurz davor, ein Workshopsystem aufzubauen, mit dem wir die Leute regelmäßig ausbilden. Ich habe auch in Arbeitsagenturen schon Vorträge gehalten, und für den Verbraucher*innenschutz haben wir auch schon einiges gemacht. Ich denke, es gibt an allen Stellen Leute, die merken: Wir sollten uns damit mal beschäftigen.
Gibt es denn aus Ihrer Sicht positive Beispiele, wie KI heute schon von Verwaltungen eingesetzt wird, die man sich genauer anschauen sollte?
ZWEIG: Insgesamt ist das ein schwieriger Bereich, aber es ist nicht auszuschließen, dass solche Systeme Ämter unterstützen könnten. Dazu muss die Korrektheit und Wirksamkeit der Anwendung dieser Systeme wissenschaftlich beobachtet und bewertet werden. Zudem muss auch der Prozess, in dem das System eingesetzt werden soll, sorgfältig vorbereitet werden. In diesem Sinne gibt es ein Positivbeispiel, wie man ein Pilotprojekt aufsetzen kann, wenn ein Staat KI einsetzt – und das ist der Arbeitsmarktservice-(AMS-)Algorithmus in Österreich. Eigentlich ist es sogar nur eine Heuristik, aber lassen Sie uns beim gängigeren Begriff „Algorithmus“ bleiben. Das System klassifiziert Arbeitslose in drei Gruppen: eine erste Gruppe, die sowieso wieder in Arbeit kommt. Eine dritte Klasse, die schon sehr lange nicht mehr in Arbeit ist und vielleicht auch nicht mehr in Arbeit kommen wird. Und eine zweite Klasse dazwischen für alle, die nicht in einer dieser beiden Gruppen sind. Diese Gruppe soll verstärkt mit Weiterbildungsmaßnahmen unterstützt werden. Es ist offensichtlich, dass das eine sehr sensible Aufgabenstellung ist und dementsprechend gut evaluiert werden muss.
Wie funktioniert das konkret technisch? Wie sortiert die KI die Antragsteller*innen?
ZWEIG: Die Heuristik, die dafür verwendet wurde, ist eine sogenannte logistische Regression, das ist eine sehr, sehr simple Form des maschinellen Lernens. Das Ergebnis ist im Gegensatz zu anderen Methoden des maschinellen Lernens noch sehr übersichtlich, da kann man als Mensch verstehen, wie welcher Faktor auf das Ergebnis einwirkt.
Welche Erkenntnisse konnte man da gewinnen?
ZWEIG: Da stellte sich heraus, dass es eine Art Strafwert gibt, wenn man eine Frau, wenn man über 50 ist oder Personen pflegt. Das resultierte medial in einem großen Aufschrei, dass diese Software diskriminierend sei. Aber das ist so nicht ganz richtig – denn die verwendete Heuristik an sich hat aus dem Arbeitsmarkt gelernt.
Die Software legt quasi eine Diskriminierung offen, aber sie diskriminiert nicht selbst?
ZWEIG: Ja, sie legt die Diskriminierung offen. Diskriminiert sie selbst? Na ja, die Software hat erst einmal überhaupt keine Akteurschaft, die „tut“ nichts im Sinne einer eigenverantwortlichen Handlung. Aber je nach Verwendung der Software wird die erkannte Diskriminierung nun unter Umständen weitergetragen. Laut dem Leiter des AMS ist der erwartete Effekt, dass die vom Arbeitsmarkt diskriminierten Personen durch den Algorithmus nun vermehrt in die mittlere Kategorie kommen – und dadurch besonders stark gefördert werden. Das wäre dann ja geradezu eine Antidiskriminierung, quasi eine Ausgleichsbewegung.
Was kann man von diesem österreichischen Beispiel lernen?
ZWEIG: Meiner Meinung nach gibt es nur eine einzige Möglichkeit, um herauszukriegen, ob solche Systeme hilfreich sind oder nicht: Wir müssen sie von Anfang an wissenschaftlich begleiten und im Gesamtsystem beurteilen, ob die Performance wirklich besser wird oder nicht. Aber das scheitert ganz oft schon daran, dass wir gar nicht wissen, wie gut die Entscheidungen der Menschen vorher waren. Oftmals herrscht – etwa im Bereich HR – das Gefühl vor, Menschen würden nicht gut genug entscheiden. Und auf dieser Grundlage soll dann was gemacht werden.
Was ist das Problem daran?
ZWEIG: Das resultiert in Aktionismus: Es wird ein System gekauft, das angeblich gut ist und das oft schon auf externen Daten vortrainiert ist. Da habe ich ein gutes Beispiel aus dem Bereich der Medizin: Da wurde ein KI-System an vielen deutschen Kliniken in Pilotprojekten ausprobiert, das Diagnosen bei Krebs unterstützen sollte – und hat das an sich auch ganz gut gemacht. Das System machte aber auch merkwürdige Vorschläge. Ein Grund dafür könnte sein, dass das System in den USA trainiert wurde, wo Ärzt*innen an den von ihnen verschriebenen Medikamenten finanziell beteiligt sind. Das hat der Rechner natürlich mitgelernt und sich dadurch teilweise für spezielle Medikamente entschieden. Was ich damit sagen will: Diese Systeme kann man eben nicht beliebig irgendwo trainieren und einfach einkaufen.
Ist das gut, dass man nicht einfach irgendein vortrainiertes KI-System kaufen kann?
ZWEIG: Ja, für mich ist es auch beruhigend. Ich werde oft gefragt, ob wir denn jetzt schon völlig abgehängt sind in Europa, weil die USA und China schon so viel weiter seien. Aber diese ganzen Beispiele zeigen immer wieder: Wenn man ein KISystem für Europa haben will, dann muss man es auf europäische Daten trainieren. Europa ist ein wichtiger Markt – aber nur gemeinsam! Und das bedeutet, das wir hier eine Machtposition haben: Wenn wir beschließen, dass mit unseren Daten anders umgegangen wird, dann gibt es wenig Alternativen für diejenigen, die Systeme für Europa entwickeln wollen, die das Verhalten von Europäern betreffen. Meine wichtigste Forderung: Unsere digitalen Verhaltensdaten sollten nicht mehr zentral gesammelt werden dürfen, um von ihnen zu lernen. Hier müssten dann dezentrale, maschinelle Lernverfahren eingesetzt werden. Hier fehlt es bislang an Infrastruktur und auch weiterer Forschung.
Damit die Marktmacht funktioniert, müssen KI-Systeme aber überwacht werden – wofür es bislang noch keine zentralen Stellen gibt. Wer sollte diese Kontrolle von KI-Systemen Ihrer Meinung nach vornehmen?
ZWEIG: Ich glaube, dass wir in den meisten sozialen Prozessen schon jeweils eine Schiedsorganisation haben: bei der Ressource Arbeit die Betriebsräte, wenn es um Verbraucher*innen geht, haben wir die Verbraucherschützer*innen, wenn es um private Medien geht, die Landesmedienanstalten. Aber diese Stellen müsste man natürlich ausrüsten mit entsprechender Kompetenz.
Viele der Fragestellungen im Bereich Arbeit und Soziales fallen aus der Perspektive der Beschäftigten – von der Einstellung über Boni, Assessments, bis hin zu Aussortierungsautomatismen, wie sie von einem großen amerikanischen Onlinehändler bereits getestet wurden, in den von Ihnen genannten, sensiblen Bereich. Ist es denn realistisch, solche Kompetenzen dezentral aufzubauen?
ZWEIG: Das ist absolut realistisch. Die Betriebsräte sind jetzt schon seit Jahren dabei, sich darüber Gedanken zu machen. Und tatsächlich ist es so: Wir machen ziemlich viele Workshops, und ganz ehrlich, man kann in 45 Minuten schon eine gewisse Bodenhaftung erreichen beim Thema KISysteme. Deswegen bin ich relativ optimistisch, dass man das Grundverständnis, wie insbesondere die maschinellen Lernverfahren funktionieren, was sie können und was sie nicht können, ganz gut und schnell auch in die Breite bekommt.
Und dann soll der Betriebsrat sich anschauen, ob die KI diskriminiert? Und ob die Daten richtig aufbereitet wurden?
ZWEIG: Nein, der Betriebsrat selber kann das nicht. Natürlich braucht es dafür Expert*innen. Aber die kommen dann auch, wenn der Markt da ist und es Angebote gibt.
Was bräuchten diese Akteure, um Künstliche- Intelligenz-Systeme tatsächlich kontrollieren zu können?
ZWEIG: Die brauchen auf der einen Seite die genannten Fachleute. Vor allen Dingen brauchen sie aber je nachdem, wie hoch das Schadenspotenzial eines solchen Systems ist, Zugang zu Daten und zu Schnittstellen, um nachvollziehen zu können, was genau passiert und ob beispielsweise diskriminiert wird. Deswegen haben wir einen Regulierungsvorschlag gemacht, der anhand von Schadenspotenzial und Grad der Abhängigkeit von einer Entscheidung verschiedene Transparenz- und Nachvollziehbarkeitspflichten aufteilt (Abbildung 1).
Wie könnte das in der Praxis aussehen?
ZWEIG: Der Kollege Wagner-Pinter in Österreich, der den AMS-Algorithmus entwickelt hat, bietet seine Software z. B. zusammen mit einem Set von sogenannten Sozialverträglichkeitsregeln an. Regeln, wie das System in der Praxis eingesetzt werden soll.
Was steht in diesen Regelwerken?
ZWEIG: Etwa: Eine Entscheidung darüber, in welcher Kategorie eine Person landet, muss immer zusammen mit dem Arbeitssuchenden besprochen werden. Diese Person darf widersprechen. Sie kann ihre Grunddaten jederzeit einsehen und ändern. Das heißt: Falls die Maschine auf Grundlage von falschen Daten eine Entscheidung getroffen hat, dann kann die Entscheidung überschrieben werden. Wenn sie überschrieben wird, muss dokumentiert werden, warum sie überschrieben wurde. Und: Das System wird jedes Jahr neu aufgesetzt, und zwar immer nur auf den Daten der letzten vier Jahre. Die Arbeitssuchenden haben damit ein Recht auf Vergessen: Schlechte Vermittelbarkeit während einer jugendlichen Trotzphase muss einen dann nicht bis ins Alter begleiten. Wir würden nun weitere technische Zugangsmöglichkeiten fordern, die es Anwält*innen erlauben, systematische Ungleichbehandlungen zu erkennen – natürlich in Zusammenarbeit mit Fachleuten.
Was spricht gegen einen KI-TÜV als Akteur, der die Kontrolle durchführt?
ZWEIG: Es ist es eben nicht das System an sich, das geprüft werden muss. Das ist nur ein Teil der Überprüfung. Wir haben ja auch nicht die eine Stelle, die gleichzeitig beurteilt, ob Ärzt*innen Fehler gemacht haben oder ob Jurist*innen korrekt arbeiten, – sondern es gibt jeweils Institutionen, an die man sich wenden kann, wenn man das Gefühl hat, dass der eine oder andere Berufsstand systematische Fehler in Entscheidungen macht. Wir brauchen zudem immer einen Ansatz, der den Gesamtprozess betrachtet, das hat das Beispiel mit dem AMS-Algorithmus gezeigt. Meiner Meinung nach brauchen wir einen Ansatz, der statt der Siegelung der Software die Standardisierung und Normierung der Qualität dieses Gesamtprozesses begleitet und auch zertifiziert. Das hätte auch den Vorteil, dass man nicht mehr verschiedene Versionen einer Software zertifizieren muss. Stattdessen muss man die Qualitätssicherung des Gesamtprozesses zertifizieren – und solange der anhand bestimmter Kriterien ständig und je nach Schadenspotenzial evaluiert wird, darf die Firma dann eben auch arbeiten. Zusätzlich benötigen wir aber eine unabhängige Institution, wenn es um staatliche KI geht.
Könnte Ihrer Einschätzung nach der Bereich Arbeit und Soziales in der Verwaltung ein Testfeld sein, um die Chancen von KI zu nutzen?
ZWEIG: Der Bereich Arbeit ist schwierig. Gerade der Bereich Arbeit ist einer, wo ich unsicher bin, ob heutige KI-Systeme komplex genug sind, um die Kontextabhängigkeit, die wir eigentlich gerne hätten, berücksichtigen zu können. Der Einsatz von KI-Systemen wird heute oftmals als alternativlos dargestellt. Aber natürlich gibt es Alternativen, z. B. bessere und mehr Beraterinnen und Berater einzusetzen. Deswegen ja: Auf der einen Seite wäre das ein interessantes Feld, weil wir viel darüber lernen könnten, wie menschliche Entscheidungen besser unterstützt werden können. Das liegt daran, dass der Computer uns zwingt, stärker zu definieren: Was heißt für uns eigentlich Erfolg? Wenn wir mehr Leute ins Arbeiten bringen? Woran wollen wir uns nachher messen? Ich glaube, dass dieser Prozess an sich sehr viel Gutes bewirken könnte. Ob wir am Ende aber Maschinen über Menschen urteilen lassen werden in diesen sensiblen Bereichen – das müssen wir breit diskutieren!
Dieses Interview stammt aus einer Publikation des Bundesministeriums für Arbeit und Soziales anlässlich der deutschen EU-Ratspräsidentschaft von Juli bis Dezember 2020. Der Begleitband informiert in wissenschaftlichen Beiträgen, Interviews, Standpunkten und Infografiken über die Schwerpunktthemen des BMAS während des deutschen Vorsitzes im Rat der Europäischen Union. Dadurch möchte das BMAS den Dialog innerhalb der EU stärken und gemeinsam mit den europäischen Arbeits- und Sozialministerinnen und -ministern EU-weite Handlungsbedarfe identifizieren. Den vollständigen, digitalen Begleitband finden Sie hier: